|
Dieser Abschnitt beschäftigt sich mit dem Entwurf der Programmbibliothek für Dokumentenmethoden, die speziell zur Bearbeitung von SGML-Dokumenten ausgelegt ist. Zunächst wird ein Konzept zur Organisation der bereitgestellten Funktionalitäten in Paketen entwickelt. Es schließt sich die Aufteilung der Funktionalitäten auf die Pakete und die darin enthaltenen Klassen an. Schließlich werden die Methoden der Klassen hergeleitet und an Beispielen erläutert. In Kapitel 5 werden die Pakete realisiert, eine vollständige Liste der Methoden findet sich in Anhang C.
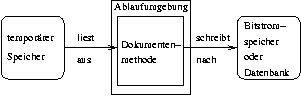
Die Programmbibliothek für Dokumentenmethoden bildet das Herz des Speichers. Hier wird den Dokumentenmethoden die gesamte Funktionalität des Speichers zur Verfügung gestellt. Die Programmbibliothek verbirgt alle Details der eingesetzten Basisprodukte. Außerdem stellt sie auch Methoden zur Verfügung, die dazu dienen den Speicher zu warten und zu konfigurieren, so daß zur Pflege kein spezielles Werkzeug erforderlich ist. Es werden einfach die entsprechenden Methoden aktiviert.
Die Entwicklung der Methoden in den von den Paketen bereitgestellten Klassen erfolgte ausgehend von der in Kapitel 4.6 beschriebenen Vorgehensweise beim Speichern von Dokumenten, die ihrerseits von den Anforderungen an den Speicher abgeleitet wurde.
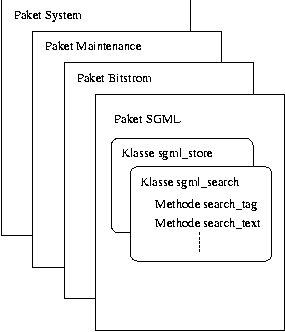
Die Methoden sind hierarchisch organisiert. Die Methoden sind zunächst in Klassen zusammengefaßt und die Klassen ihrerseits in Pakete (packages). So kann man sich z.B. ein Paket mit Namen SGML vorstellen, das die Klassen sgml_store und sgml_search bereitstellt, die erste beinhaltet Operationen zum Speichern, die zweite Operationen zum Durchsuchen eines Dokuments. Die Klasse sgml_search könnte ihrerseits Operationen, wie z.B. search_tag zum Auffinden eines bestimmten Tags oder search_text zum Auffinden eines bestimmten Textstrings in einem gespeicherten SGML-Dokument, (s. Kap. 2.1) beinhalten. Abbildung 4.3 soll das Paket-Klassen-Konzept verdeutlichen.
Durch das Gruppieren der Klassen (packaging) und damit der beinhalteten Methoden ist es einfach, die Programmbibliothek um neue Funktionalitäten zu erweitern und an gesamtsystemspezifische Gegebenheiten anzupassen. Diese Klassifizierung der zur Verfügung stehenden Operationen ermöglicht weiterhin einen übersichtlichen und organisierten Zugriff auf die einzelnen Operationen und vermeidet weitgehend Namenskonflikte der Methoden. Weiterhin ist es möglich, das gleiche Paket in unterschiedlichen Entwicklungsstufen (Versionen bzw. Releases) bereitzustellen und somit Abwärtskompatibilität zu gewährleisten.
So kann man sich folgende einfache Klassifizierung der Methoden vorstellen:
Natürlich kann es Klassen geben, die mehreren Paketen zugeordnet sind. Beispielsweise könnte eine Methode, die den Dokumententyp eines SGML-Dokuments ausliest, im Paket-System und im Paket-SGML zu finden sein. Eine Dokumentenmethode, die zur Bearbeitung mehrerer Dokumenttypen dient, würde eine solche Methode benötigen, wie auch der Speicher, der grundsätzlich ermittelt um welchen Dokumenttyp es sich bei einem hinterlegten Dokument handelt, damit die Document Type Definition (DTD) des Dokuments immer nur einmal vorgehalten werden muß.
Dem Bitstrom-Paket und dem SGML-Paket hingegen kann eine detailiertere Funktionalität zugeordnet werden, da die Vorgehensweise beim Speichern und damit auch die Bedingungen für den Zugriff auf die Dokumente bekannt sind. Im folgenden werden die Klassen dieser beiden Pakete näher spezifiziert.
Die Pakete Bitstrom und SGML sollen Klassen bereitstellen, die das Speichern und Durchsuchen von strukturiert oder als Bitstrom vorliegenden Dokumenten ermöglichen. Es werden prinzipiell vier Klassen benötigt:
Die Definition der Methoden dieser Klassen, die ihrerseits die bereits erwähnten atomaren Operationen realisieren, folgt in den nächsten Abschnitten.
Die Trennung der Funktionalität in Pakete und Klassen erfolgt auf dieser Ebene, um die Operationen einzeln zu entwickeln. Aus der Sicht einer Instanz, die Aufträge an den Speicher übermittelt, bilden sie eine einheitliche Schnittstelle zum Zugriff auf den Speicher.
Das Speichern von Bitstromdaten ist eine verhältnismäßig einfache Aufgabe. Eine entsprechende Methode liest eine Anzahl von Bytes (oder Bits) aus dem temporären Zwischenspeicher, gegebenenfalls operiert sie auf den Daten (z.B. Dekomprimierung) und schreibt sie dann in den Bitstromspeicher. Ein einfacher Algorithmus in Python zum Speichern eines Bitstroms ist in Abbildung 4.5 gegeben.
Für SGML-Dokumente stellt sich diese Aufgabe etwas schwieriger dar. Im Kapitel 2.1 wurde erläutert, aus welchen Elementen sich ein SGML-Dokument zusammensetzt, aus sogenannten Tags und den Taginhalten. Desweiteren benötigt man zur vollständigen Beschreibung eines SGML-Dokuments, dessen Document Type Definition (DTD). Um das Dokument zu speichern, muß die DTD nicht näher betrachtet werden, es muß lediglich sichergestellt werden, daß der Speicher bei Bedarf auf die DTD zugreifen kann.
Bei den im folgenden entwickelten Operationen zum Speichern von Dokumenten wird davon ausgegangen, daß diese in Normalform vorliegen. Das heißt, das Dokument ist vollständig strukturiert, es dürfen keine Endtags weggelassen werden. Da frei verfügbare SGML-Parser für alle Plattformen existieren, bedeutet dies keine Einschränkung.
Um komfortabel aus dem im Zwischenspeicher gehaltenen SGML-Dokument lesen zu können, bedarf es Methoden, um die einzelnen Elemente nacheinander einzulesen und die Attribute der Tags zu ermitteln. Weiterhin müssen Funktionalitäten vorgehalten werden, um den Strukturbaum des SGML-Dokuments speichern zu können, da dieser wie in Kapitel 2.2 für eine Reihe von Operationen benötigt wird. Das heißt, es muß möglich sein, nur die Tags eines SGML-Dokuments sequentiell auszulesen und im Speicher abzulegen.
In Abbildung 4.6 ist ein einfacher Algorithmus zur Speicherung eines SGML-Dokuments in der Datenbank dargestellt.
|
obj=c_sgmlstore() # instanziiere SGML-Speicherobjekt obj.open_in() # oeffne Eingabe-Bitstrom obj.save_doctype() # speichere DTD in der Datenbank # lese solange naechstes SGML Element bis # das Ende des Eingabe-Bitstroms erreicht ist buff="  " "while buff!=None: buff=obj.get_nextsgmlelement() # wenn es ein Tag ist speichere es in der # Tagklasse, sonst speichere es als Text # in der Datenbank if obj.is_tag(buff): obj.save_astag(buff) else: obj.save_astext(buff)
|
Eine Methode (get_nextsgmlelement), die unabhängig vom Elementtyp das nächste SGML-Element aus der temporären Datei liest, ist unverzichtbar. Stehen nur Methoden zur Verfügung, die lediglich bestimmte Elementtypen einlesen, muß der Autor der Dokumentenmethode immer die Reihenfolge der Elemente berücksichtigen, was zu einem nicht unerheblichen Mehraufwand bei der Programmierung führen würde.
Wie in Kapitel 4.6 beschrieben, wird beim Speichern in der Datenbank, nach Markup (Tags), Text und Binärdaten unterschieden. Daher ist es sinnvoll bereits beim Lesen aus dem Zwischenspeicher Mechanismen bereitzustellen, die ebenfalls diese Unterscheidung erlauben. Da beim Einlesen des nächsten Elements nicht bekannt ist, um welchen Elementtyp es sich dabei handelt, gibt es Methoden, die den Typ feststellen (is_tag, is_text, is_bin). Allerdings stößt man hier bei der Realisierung auf das Problem, Text und Binärdaten zu unterscheiden.
Neben der Methode zum Speichern eines Tags in der Datenbank (save_astag) existieren noch zwei weitere Methoden (save_astext, save_asbin) zum Ablegen der anderen beiden Elementtypen in den Datenbankklassen.
Ein weiteres Beispiel, das nur den Strukturbaum eines Dokuments abspeichert und dabei ein bestimmtes Tag überspringt, ist in Abbildung 4.7 dargestellt.
|
obj=c_sgmlstore() # instanziiere SGML-Speicherobjekt obj.open_in() # oeffne Eingabe-Bitstrom obj.save_doctype() # DTD in der Datenbank speichern # lese solange naechstes SGML-Tag bis # das Ende des Eingabe-Bitstroms erreicht ist buff = "  " "while buff != None: buff = obj.get_nexttag() # sonst speichere Tag in der Datenbank
|
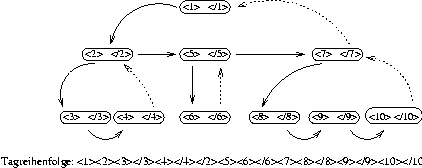
Die Berechnung des vereinfachten Strukturbaums (Kap. 2.1) erfolgt zur Laufzeit der Dokumentenmethode. Dabei werden die Tags in der Reihenfolge, in der sie mittels der Methode save_astag abgelegt werden betrachtet und Bruder- und Sohn-Felder nach folgenden Regeln berechnet:
In Abbildung 4.8 sollen diese Zusammenhänge veranschaulicht werden.
Die Linien zeigen den Weg, der beim Durchlaufen des Baums mit Depth-First-Search abgeschritten wird. Die schwarzen Linien verdeutlichen die Vater-Sohn- bzw. Bruder-Beziehungen, die gepunkteten Linien vervollständigen den Weg. Der Einfachheit halber wurden die Tags numeriert. Korrespondierende Start- und Endtags stehen jeweils in einem Knoten, damit die Aufteilung der Teilbäume deutlicher wird. Mathematisch korrekt wäre es, die Endtags als (rechten) Bruder des Starttags darzustellen.
Zum Durchsuchen aller gespeicherten Dokumente nach und/oder-verknüpften Begriffen wird der Volltextindizierer verwendet. Es wird eine Methode vorgesehen, die unter Benutzung der Schnittstelle zum Volltextindizierer, alle als Bitstrom gespeicherten Dokumente nach einem gegebenen Ausdruck durchsucht. Der Aufbau des Ausdrucks, sowie die Möglichkeiten zur Konfiguration hängen von der Auswahl des Indizierers ab. Da für die Schnittstellen von Volltextindizierern bislang keine Standardisierungsbemühungen existieren, ist es nicht möglich zu diesem Punkt genauere Vorgaben zu machen. Selbst reguläre Ausdrücke finden nur teilweise Verwendung bei den derzeit verfügbaren Indizierern. Als minimale Anforderung wird die Suche nach und/oder-verknüpften Begriffen definiert.
Eine weitere Möglichkeit die Dokumente auf bestimmte Merkmale zu prüfen, ist die Tag-Klasse der Datenbank zu durchsuchen. Dies ist in Kombination mit der Auswahl einer bestimmten DTD von Interesse. Hat man beispielsweise Kenntnis über die Semantik eines bestimmten Tags oder einer DTD, dann muß es Methoden geben, die folgende Dokumente aus dem Speicher selektieren können:
Als Ergebnis wird eine Liste der entsprechenden Dokumenten-ID’s zurückgegeben. Um diese Funktionalität zu erreichen, bedarf es dreier Methoden: Eine, die zu einer gegebenen DTD alle Dokumente findet, die auf dieser DTD basieren, eine, um die Tag-Klasse nach einem gegebenen Tag zu durchsuchen, die Dritte kombiniert die beiden vorigen und findet alle Dokumente, die einer bestimmten DTD entsprechen und ein gegebenes Tag beinhalten.
Die beschriebenen Funktionalitäten dienen dem Auffinden eines Dokuments im Speicher. Im folgenden werden Operationen definiert, die zum Zugriff auf ein bestimmtes Dokument benötigt werden. Zunächst sind ein paar grundlegende Methoden zu definieren, um das gesamte Dokument auszulesen, den Strukturbaum eines Dokuments zu erhalten und die DTD eines Dokuments zu erfragen.
Für den byte-orientierten Zugriff stehen Methoden bereit, wie sie bereits beim Auslesen der temporären Datei beschrieben wurden. Der strukturierte Zugriff auf ein Dokument geschieht immer über Tags, da diese wie unter Kapitel 2.1 beschrieben, die Struktur des Dokuments manifestieren. Vorausgesetzt wird bei dieser Vorgehensweise immer die Kenntnis über die Struktur des Dokuments, die über die oben beschriebenen Operationen erlangt werden kann. Es werden Methoden bereitgestellt, die das n-te Tag oder alle Tags eines gegebenen Typs auffinden und dessen Inhalt (das von Start- und Endtag eingeschlossenen Dokumentenstück) auslesen können. Weiterhin stehen Methoden zum Auslesen der Attribute und der Anzahl der vorkommenden Tags eines Typs zur Verfügung.
Als Beispiel findet sich in Abbildung 4.9 eine Dokumentenmethode, die als Ergebnis ein Inhaltsverzeichnis aller Kapitel des Dokuments zurückgibt.
|
obj=c_sgmlquery() # instanziiere Zugriffsobjekt # initialisiere Lauf- und Ergebnisvariablen n=1 erg=["  ",0] ",0]contents=   # solange noch ein entsprechendes Tag gefunden wird while erg!=["",0]: # hole n-tes KAPITEL-Tag aus DB erg=obj.sgmlquery_tag("KAPITEL",n) # rette Tag in Ergebnis Array contents[erg[1]]=erg[0] n=n  1 1return contents # gebe Ergebnis zurueck
|
Über den Zugriff auf und die Speicherung von Dokumenten-Metadaten im Speicher kann keine definitive Aussage getroffen werden, da diese in Abhängigkeit vom Gesamtsystem festgelegt werden. Es ist aber positiv davon auszugehen, daß eine eindeutige Dokumenten-ID, ein Eigentümer, ein Autor und ein Name (Titel) zu jedem Dokument vorgehalten werden. Hier werden Methoden vorgesehen, die es ermöglichen nach eben diesen Merkmalen zu suchen und die ebenfalls eine entsprechende Liste mit Dokumenten-ID’s zurückliefern.