|
Das Speichern von SGML-Dokumenten kann in vielfältiger Weise geschehen. Im folgenden sollen einige repräsentative Verfahren erläutert werden.
Man speichert bzw. archiviert Dokumente, weil man zu einem späteren Zeitpunkt wieder darauf zugreifen möchte. Die Art des Zugriffs resultiert im wesentlichen aus der Art, auf die das Dokument gespeichert wurde. Um komfortabel auf SGML-Dokumente zugreifen zu können, benutzt man Kenntnisse über die Struktur des Dokuments bereits beim Speichern. Diese Kenntnisse werden entweder aus der DTD, aus dem SGML-Dokument selbst oder aus beiden gewonnen. In allen Fällen versucht man das Wissen über den strukturellen Aufbau der SGML-Dokumente zu nutzen, um später effizienter und effektiver darauf zugreifen zu können.
Die verschiedenen Methoden ein SGML-Dokument zu speichern bieten verschiedene Möglichkeiten auf den SGML-Dokumenten zu operieren. Im allgemeinen unterscheidet man zwischen Operationen, die Kenntnis über den strukturellen Aufbau des Dokuments haben (strukturorientierte Operationen) und solchen, die ohne jegliche Kenntnis über die Struktur operieren (strukturunabhängige Operationen). Erstere operieren meist effizienter auf den Dokumenten, während zweitere meist mit wesentlich weniger Aufwand zu realisieren sind.
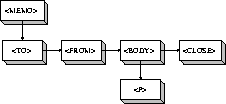
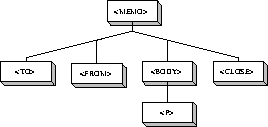
Ein wichtiges Merkmal eines SGML-Dokuments ist der Strukturbaum. Der Strukturbaum stellt die Tag-Hierarchie des Dokuments dar. Er wird benutzt, um ein SGML-Dokument darzustellen oder nur bestimmte Abschnitte zu bearbeiten. Exemplarisch wird der Strukturbaum des in Abbildung 2.2 gezeigten SGML-Dokuments in Abbildung 2.4 dargestellt.
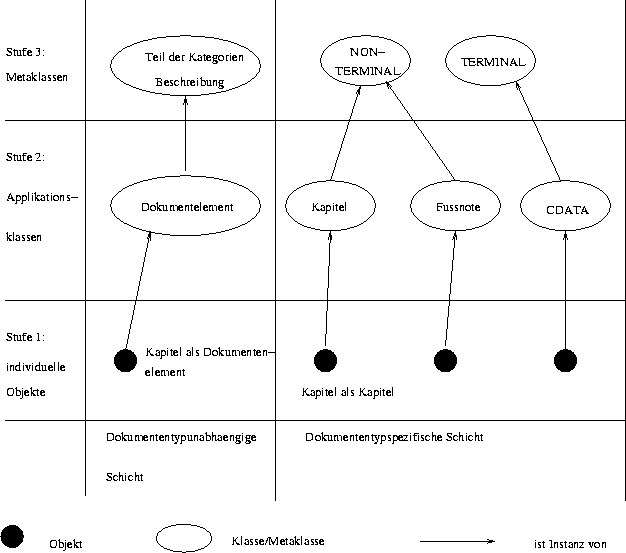
Grundsätzlich wird zwischen Markup und Daten unterschieden, mit Daten sind z.B. Texte, binäre Bilddaten, Tondaten, usw. gemeint. Unter einem Bitstrom versteht man eine Menge von Informationen, die bit- oder byteorientiert, z.B. als Datei auf einem Massenspeicher abgelegt sind. Mit Klassen sind die Dateien in einer Datenbank bezeichnet. Dieser Terminus kommt aus der Welt der objekt-orientierten Datenbanken (ODBMS), dort werden Datenstrukturen als Klassen bezeichnet.
VODAK bildet also die Informationen aus der DTD auf eine Klassenhierarchie ab, das eigentliche SGML-Dokument wird dann durch Instanzen dieser Klassen beschrieben. Auf diese Weise ist es möglich, auf jedem einzelnen Elementtyp eines SGML-Dokuments Operationen zu definieren, die in Methoden der korrespondierenden Klasse realisiert werden. Ein SGML-Dokument kann man sich derart realisiert, als einen Baum vorstellen. Die Teilbäume des Baums sind Instanzen der verschiedenen Klassen der dokumenttypabhängigen Schicht. Die Methoden, um in diesem Baum suchen zu können, werden in der dokumentunabhängigen Schicht definiert und erlauben beispielsweise folgende Abfragen:
VODAK bietet uneingeschränkten Zugriff auf die gespeicherten SGML-Dokumente und die dazugehörigen DTD’s. Als Abfragesprache wurde die Vodak Query Language (VQL), für die Definition der Klassenhierarchie die Vodak Modelling Language (VML) entwickelt. Weiterführende Informationen findet man unter [KNS90] oder [BAH94].
Für das genannte Beispiel stellt sich das wie in Abbildung 2.6 gezeigt dar.
Eine Möglichkeit ist, den Strukturbaum in einer Klasse zu speichern und die Inhalte der Elemente (Daten) in einer anderen Klasse. Dabei können die Daten entweder direkt in die Datenbank eingebunden werden oder nur als Referenz auf Bitströme vermerkt sein. Zu jedem Knoten des Baums werden eine laufende Nummer, die Nummer des Vaters, des Sohnes und des Bruders gespeichert. Auf diese Art kann man den Baum bequem mittels Depth-First-Search ([Knu73]) traversieren und dabei die gewünschte Operation ausführen.
Eine weitere Möglichkeit ist, jede DTD einer Bewertung zu unterziehen und bestimmte Teile des Markups als Index-Tags auszuzeichnen. Die Index-Tags und deren beinhaltete Daten werden in einer Klasse vorgehalten, die restlichen Informationen in einer anderen. Dadurch verkleinert man die zu durchsuchende Datenmenge. Die Bewertung der DTD’s muß allerdings manuell durchgeführt werden, was einen nicht unerheblichen Mehraufwand bedeutet.